Big Data/künstliche Intelligenz
Big Data wird definiert als Sammlungen großer und komplexer Datensätze, meist aus verschiedenen Datenquellen, die nur schwer in klassischen Datenbanken gespeichert oder mit klassischen Datenbankverfahren verarbeitet werden können. Es bezeichnet Daten-Mengen, die zu groß oder zu komplex sind oder sich zu schnell ändern, um sie mit händischen und klassischen Methoden der Datenverarbeitung auszuwerten. Dabei geht es nicht nur um Datenvolumen und Größe; es geht auch darum, dass Daten i.d.R. für einen bestimmten Zweck erhoben wurden und spätere Auswertungen oft aus einer anderen Perspektive erfolgen sollen. Die Herausforderung ist, richtige Erkenntnisse aus solchen komplexen und heterogenen Langzeitdaten abzuleiten.
Nachfolgende Merkmale charakterisieren Big Data:
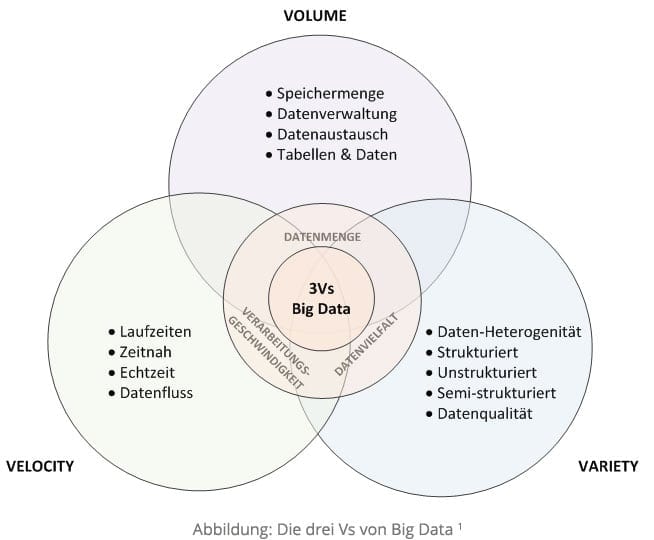
Volume (Datenmenge) – bezeichnet die riesigen Datenmengen in Bereichen von mehreren Terabytes. Bei solchen großen Speichermengen lagern die Daten üblicherweise in virtualisierten Clustern oder in der Cloud. Die (Speicher-) Server werden innerhalb der IT-Infrastruktur bedarfsgerecht gesteuert.
Variety (Datenvielfalt) – verdeutlicht die Heterogenität, in der die Daten strukturiert sind. Die Daten existieren meist in unterschiedlichen Strukturformen, Formaten und liegen in unterschiedlichen Quellsystemen vor. Da die Daten von unterschiedlichen Personen in das System „eingepflegt“ werden, ist auch die „Wahrhaftigkeit“ der Daten, die sogenannte veracity aus Sicht der Unsicherheit bzw. Inkonsistenz zu hinterfragen. Ein wesentliches Kriterium bei der Datenvielfalt ist demnach die Qualität der Daten.
Velocity (Verarbeitungsgeschwindigkeit) – beschreibt die Geschwindigkeit, mit der die Daten verarbeitet und analysiert werden. Eine Verarbeitung kann dabei entweder zeitnah oder in Echtzeit ablaufen.[1]
1 Quelle: orientiert an Russom, 2011, S. 6
Video
Doku: „Der große Umbruch – wie Künstliche Intelligenz unser Leben verändert“
www.daserste.de:
https://www.daserste.de/information/reportage-dokumentation/dokus/videos/der-grosse-umbruch-video-102.html